
If Only Production Incidents Could Speak
Thursday, July 18, 2019
Below are the slides and extended speaker notes from my talk on July 18, 2019, at OSCON 2019 with the same title as this post. See my prior posts for related material:
- Taming the Rate of Change (November 19, 2018)
- Incidents — Trends from the Trenches (Feb 26, 2019)
The Setup

- I have a lot of stories to tell you after studying over 1500 production incidents over the past year. But since these are far too many, And we’ve only about 30 minutes, we will focus on patterns in broad strokes, and reemphasize some practices.
- Why study incidents? First, I have several accumulated opinions, and I needed a way to shake those up to form better hypotheses grounded in reality. Second, most companies belong to “we’ve too much to do” category. No team has time to implement all the best practices in the world in their architectures to be highly fault-tolerant, elastic, flexible, and cheap. Trade-offs are essential. You’ve to pick and choose what you want to work on and why. An analysis like this provides you with some patterns to focus on.
- I will cover four topics in this talk — (1) cultural inhibitors in the industry about production incidents, (2) how I approached incident analysis, (3) some key patterns observed, and (4) some hypotheses and recommendations.
Slides and Notes

You’re in the right place for the slides and notes.
Cultural Inhibitors

- One of the things I realized when studying incidents is that the time you spent after incidents is as important, if not more important than the time spent during an incident. That’s because incidents tell you a lot about your architecture, your investments, your processes as well as your culture.
- However, a few cultural inhibitors prevent us from learning from incidents.
Cultural Inhibitor 1: Single Root Cause Fallacy

- This is the traditional model of looking at incidents, which is why most incident reporting systems still include fields like “root cause” and “component”. In this model, you look for a particular component or activity that caused the incident.
- The hypothesis behind this point of view is that, if only such and such component had not failed, or if someone did a particular activity exactly as it was supposed to be done, the incident could have been averted.
- For instance, whenever there is a hardware component failure is involved in an incident, the focus tends to shift to that component. Ultimately the vendor that sold that component gets called into the incident, and asked to provide a “root cause analysis”. I’m aware of stories where some of these vendors reply with “canned root cause analysis” reports to please their customers.
- However, most large-scale complex systems are always under some stress, and yet appear to operate in stable zones. When certain conditions align, they get pushed into unstable zones, causing customer impact. We call this- as an incident.
What Caused the King’s Cross Fire?

- This is a great example to dispell the single root cause fallacy, thanks to my colleague Ian Butcher who shared this with me some time ago.
- What caused the fire? Was it the match? The wooden steps in the escalator? 20 years of layers of old paint on the ceiling? Staff not knowing how to the water fog equipment to put off such fires?
- Read more about this on the Wikipedia.
Swiss Cheese Model
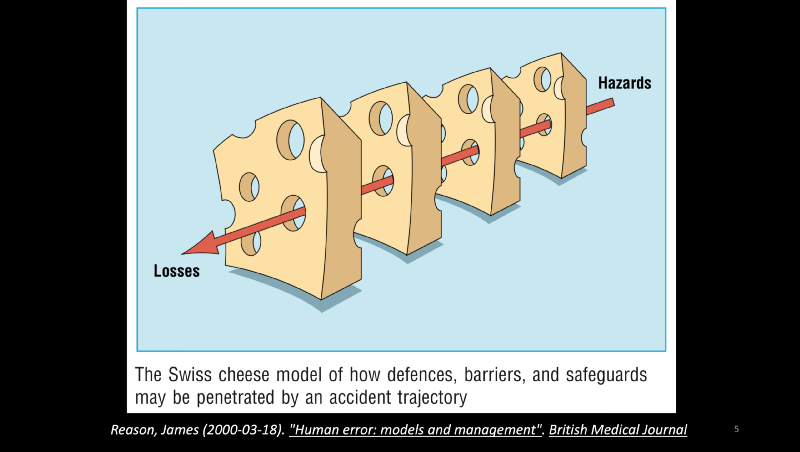
- James Reason’s 2000 paper titled “Human Error: Models and Management” describes the Swiss Cheese model to make a point that accidents occur when several hazard conditions align.
- In this paper, the author differentiates between two styles of understanding human error — the person approach, and the system approach. In the person approach, you look for first-order causes, like the mistakes a person did to cause an accident. In the system approach, you look at systemic factors and try to improve the system.
- Each hole the slice is a latent hazard condition. When some of those conditions align, you have a loss.
- You will see this in the recent HBO series on Chernobyl. Chernobyl didn’t explode because one single component failed or one person or team didn’t follow the procedure. The protagonists show several systemic failures over the years that lead to the Chernobyl disaster. These included technology, people, culture, processes, and leadership.
Cultural Inhibitor 2: Not Supposed to Happen

- It is not uncommon to see teams treat incidents as events that are not supposed to happen, except when someone didn’t do their job are they are supposed to do, or some system didn’t work as it is supposed to.
- We play heroics when they happen. We congratulate on incident recoveries. We then hurry to get back to business as usual.
- This mindset that incidents are not supposed to happen also prevents us from learning from incidents.
Cultural Inhibitor 3: The “Big Ones” vs the Rest

- High impact incidents steal our attention. We always remember the “big ones”. We talk about those for months/years. We give plenty of attention to the big ones in social media and the press.
- Low impact incidents, on the other hand, languish for our attention. We quickly forget them. In most enterprises, teams don’t write postmortems or look for improvements.
- This is natural because it’s not obvious why you should spend time on low-impact incidents.
- However, this attitude also prevents you from learning from incidents. Every incident is a signal from your production environments about the state of your architecture, your tech debt, your processes, and culture. You can’t improve any of these unless you pay attention to these signals.
- Every incident matters, and yet, you can’t treat each as a snowflake. So, how do you study incidents?
Approach — Don’t categorize

- If you’re interested in learning from incidents, toss out incident categorization like this.
- Bad way: Database, Network, Storage, Server, Vendor, Partner, DevOps, …
- When you categorize incidents like this, you tend to point fingers to particular components in your architecture. You can produce nice reports, but you will miss opportunities for systemic improvements.
Approach: Look for Patterns Instead

- Look for patterns instead. Patterns may tell you a different story from any particular incident.
- As I spent more time studying incidents, I realized that focusing on patterns helps us make better value-based arguments to make sustainable improvements.
- Otherwise, you will get frustrated that your post-incident processes like post-mortems, availability scorecards, error budgets, etc are not working, and you’re not making the impact you hoped to.
- Let us look at five common patterns from the incidents I studied.
Pattern 1: Changes
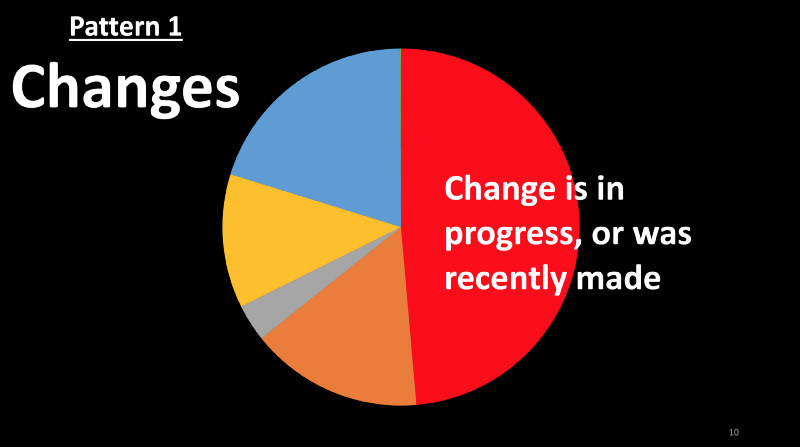
- The first pattern that came up in my analysis is production changes. A change may be a release of new code, or a config change, or maybe even an A/B test.
- I find that a majority of incidents happen when a change is in progress or was recently made.
- In my first analysis last fall, changes accounted for about 70% of the customer impact. In the second analysis on a larger set of incidents that occurred in 2018, change triggered impact was about 35%. In my most recent round, about 50% of the impact was triggered by production changes.
- Often the impact was immediate. You start to notice an impact some key business metric and then realize that the change was botched.
- In some cases, changes introduce latent failures that stay dormant for days. Those are difficult to debug or reproduce and can be frustrating to deal with. We will cover those later in this talk.
- Let’s look at some well-publicized examples in the industry.
Twitter Incident Last Week
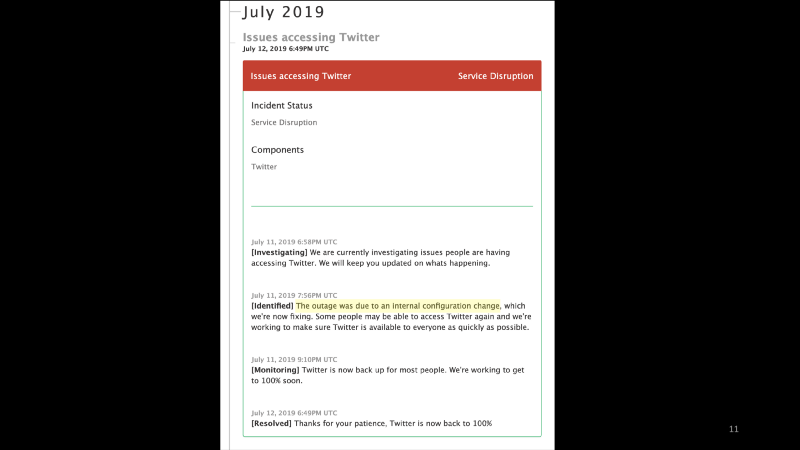
- Twitter had an incident last week. They reported that “the outage was due to an internal configuration change”.
Google Blob Storage Incident in March 2019

- Take a look at this postmortem report published by Google in March this year. Google’s internal blob storage had an outage. Their postmortem reported that “SREs made a configuration change which had a side effect of overloading a key part of the system for looking up the location of blob data”. Boom!
Facebook, Instagram, WhatsApp Incident in March 2019
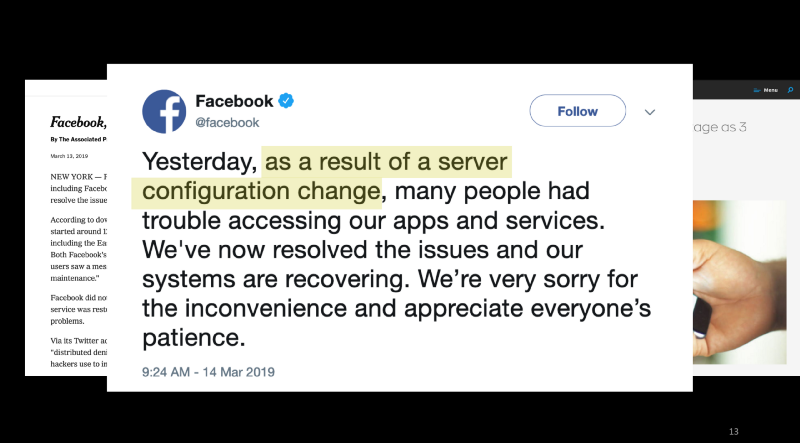
- You may recall a Facebook incident in March when Facebook, Instagram, and WhatsApp simultaneously suffered a massive outage. The next day, Facebook posted a cryptic tweet attributing the incident to a “server configuration change”.
Google 2016 Paper: “Evolve or Die: High-Availability Design Principles Drawn from Google’s Network Infrastructure”

- There isn’t a lot of industry research that shows similar patterns, except this 2016 paper from Google which reports that “a large number of failures happen when a network management operation is in progress within the network”. No wonder.
- These are not anomalies. Most enterprises have many examples like this. I’ve seen hundreds of examples where I work.
- Are these companies incompetent and don’t know how to make changes to their production incidents? I don’t think so. All these companies run incredibly complex systems at large scale, and changing such systems is hard.
- Let me offer a few hypotheses on why.
First, More changes ⇒ More entropy
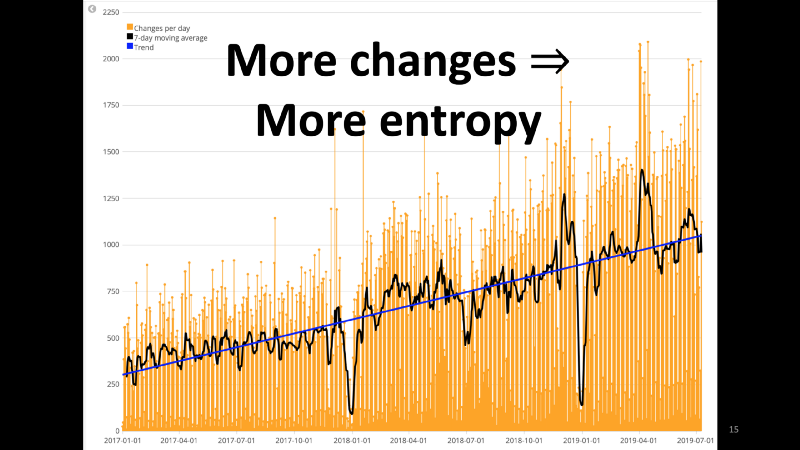
- At the Expedia Group, where I work, we make a few thousand changes a day. As we made steady progress in our cloud investments, we see a near-linear increase in the number of daily production changes.
- Why does this matter? With each change, you’re adding to the entropy that already exists in the production environment. In addition to features and bugs in your code, you’re also introducing new failure modes or revealing existing failure modes.
- Do note that, a vast majority of the changes are successful. In one particular batch of incidents over 6 months, I noticed that just about 5 out of 10,000 changes triggered a production impact.
Second, Difficult to Know Second/Higher-Order Effects
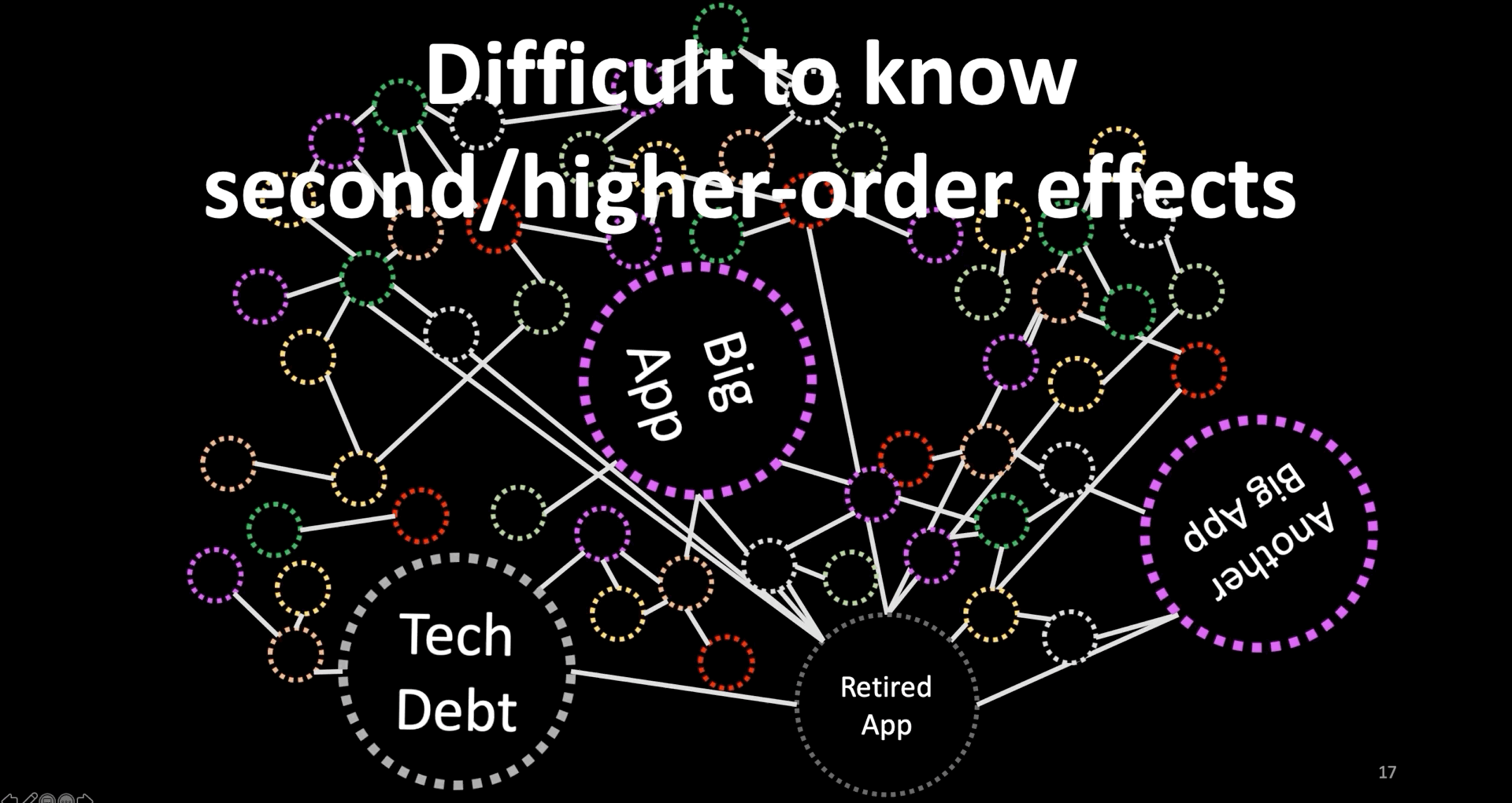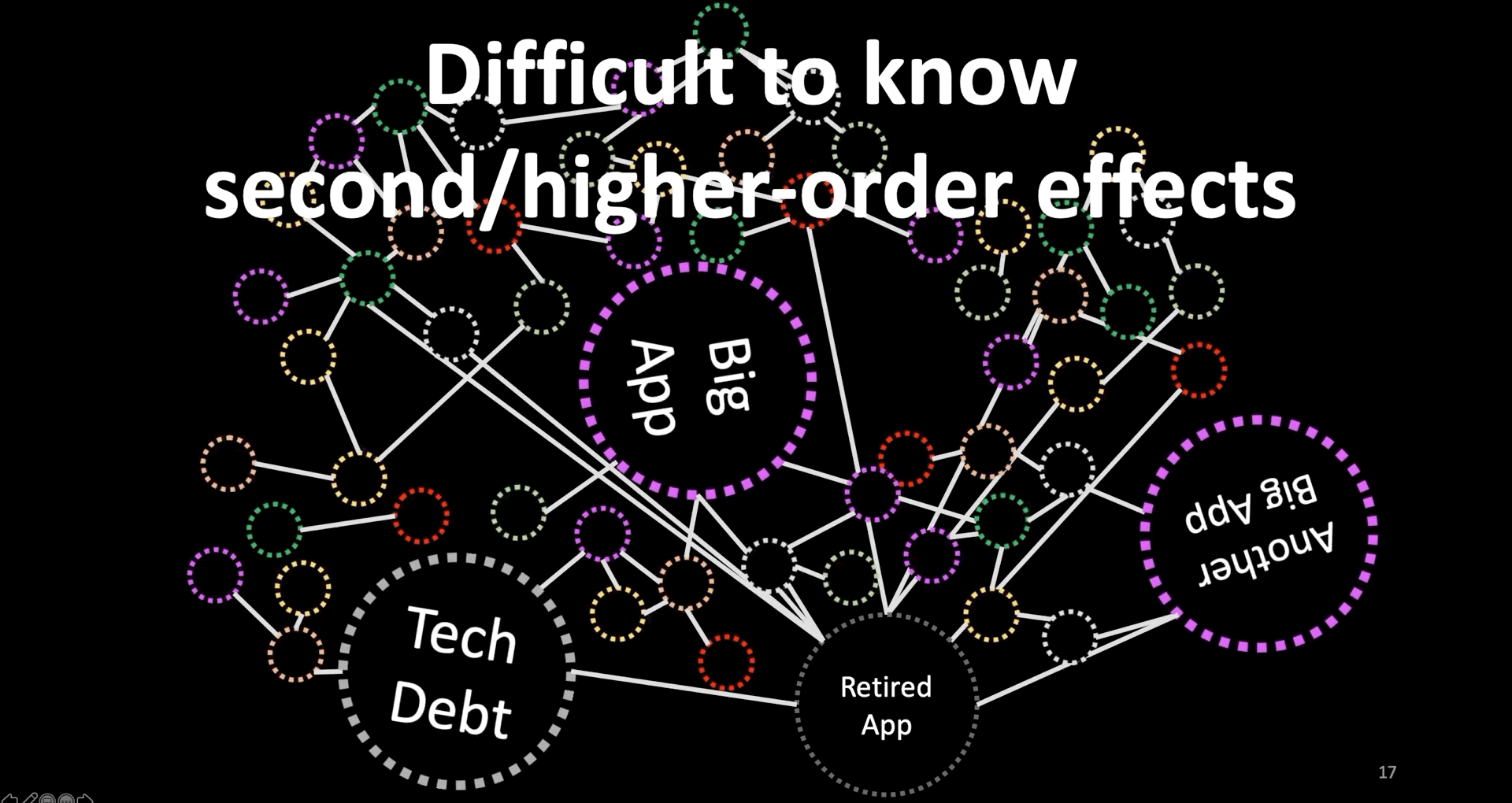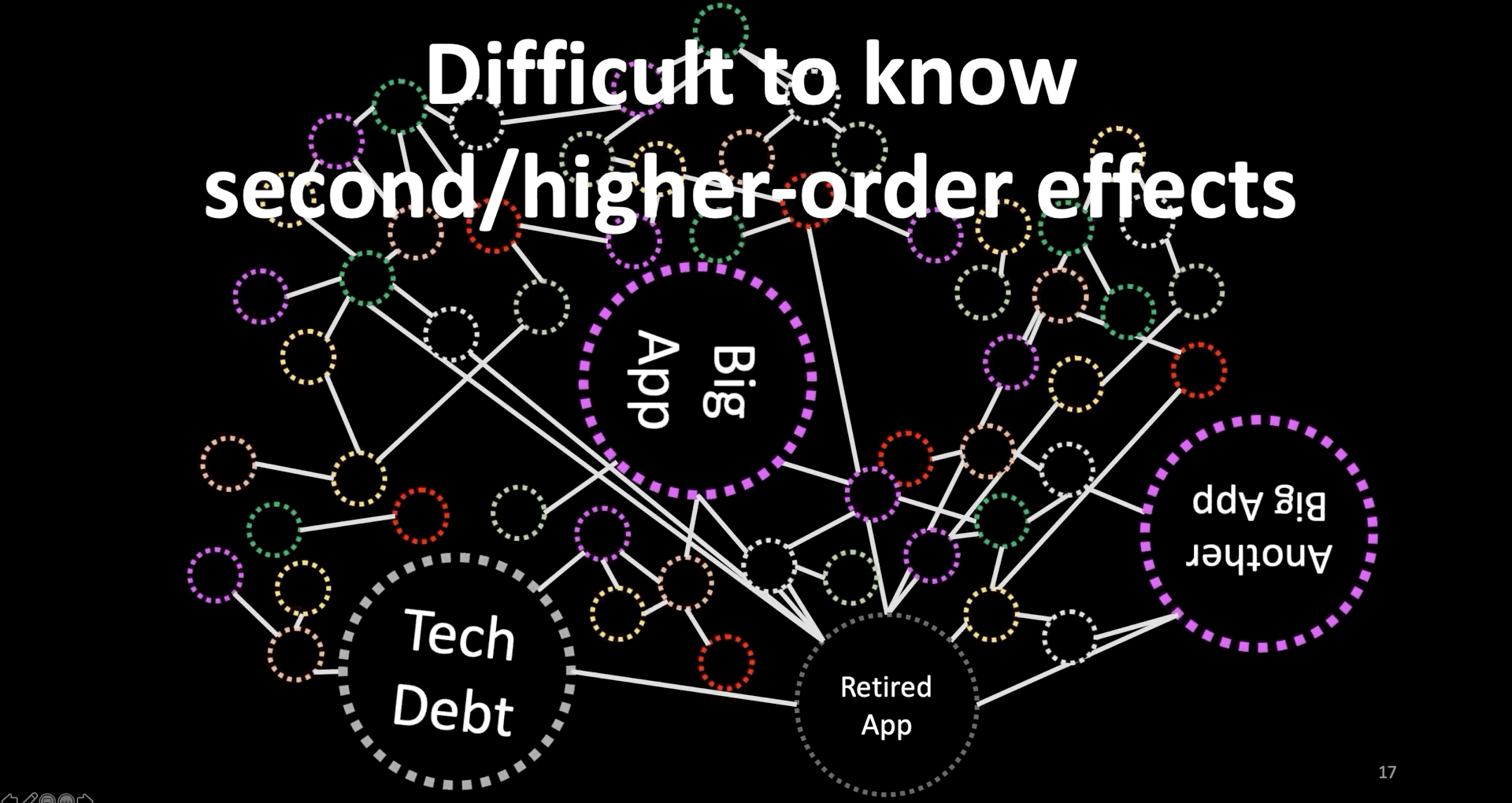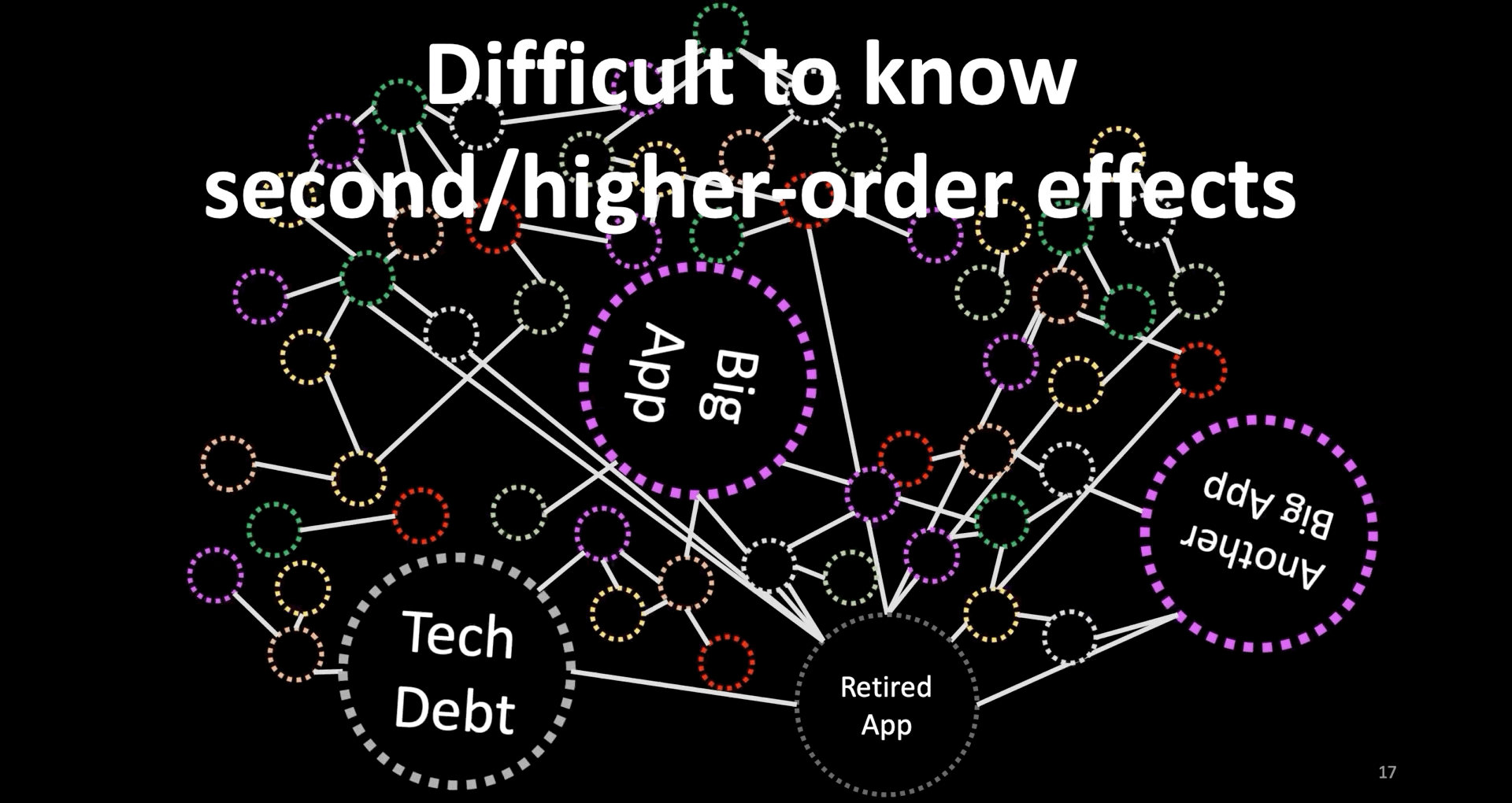
- As we invest to reduce the size of our code through micro-services, and CI/CD, complexity is shifting to connectedness.
- This connectedness is increasing the chance of success (which is to quickly create more customer value) or failure (which is the difficulty to comprehend).
- Furthermore, our production environments include a mixture of fast-changing and slow-changing systems including those that we can’t get rid of like those big circles on this slide.
- These make it difficult to know or predict second- higher-order effects of changes.
Every Change is a Test in Production

- Consequently, every change feels like a test in production. There is no escaping from this.
- Pre-prod testing can help, but no amount of pre-prod testing can make production changes predictable and safe.
- Due to high entropy, it is getting harder to mimic production environments to test changes. Our pre-prod environments, when they exist, lack the same entropy and scale that our production environments offer.
- Let’s get comfortable with this trend.
Pattern 2: Latent Failures

- The second pattern I observed is latent failures.
- These remain hidden in the environment for days, weeks or even months and don’t immediately cause issues. These wait for conditions to align, just like the swiss cheese in James Reasons’ swiss chess model.
- Example: Config changes caught when nodes are recycled or scaled up days later.
- Example: A change was made to a service behind a cache. The cache hid the fault for a few days until the cache was refreshed.
- Example: Auto-scaling kicks in to scale up a cluster, and new nodes pick up the wrong config.
Config Drift
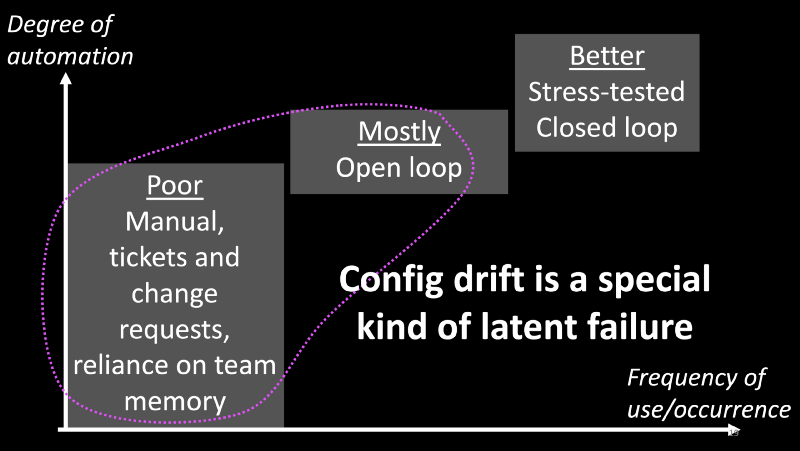
- Config drift is a special kind of a latent failure.
- Why do we have config drift? That’s because we rarely automate everything. We automate more frequently used workflows or more frequently occurring conditions, and leave the less frequently used ones in our backlogs. Those backlogs rarely shrink.
- Unfortunately, those low-frequency workflows end up relying on tickets, manual steps, change requests, and team memory. Very few people would know how to make those changes, and when they leave or change teams, any knowledge leaves with them.
- Any automation we do in the low-frequency areas is often open-loop, meaning that there is no observer to monitor and correct config drift. Over time, systems drift from their desired state.
- I saw several drift related incidents with switches, routers, firewalls, and databases which don’t get as much automation love as CI/CD for stateless apps do.
- One particular example I remember is a database failover. The automation let the active node failover to the passive node, but the passive node remained in the read-only state due to configuration drift.
- In another case, a redundant firewall device failed to take over when the primary device failed. It turned out that someone manually made a config change several months before the incident, and forgot to undo it.
Pattern 3: Mismatched Assumptions
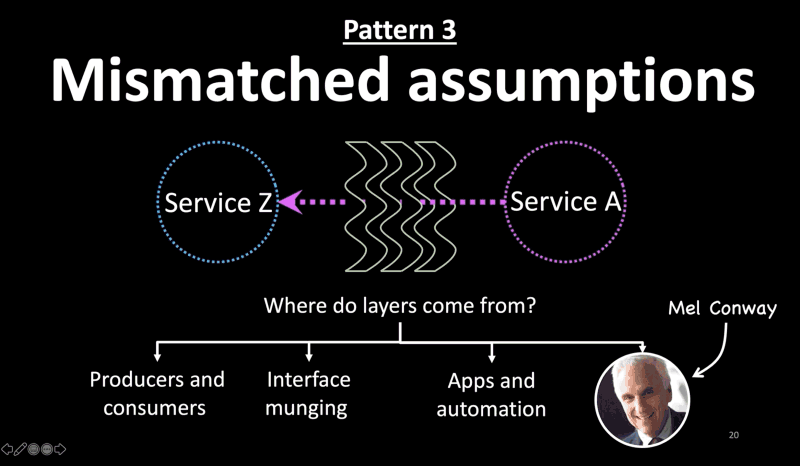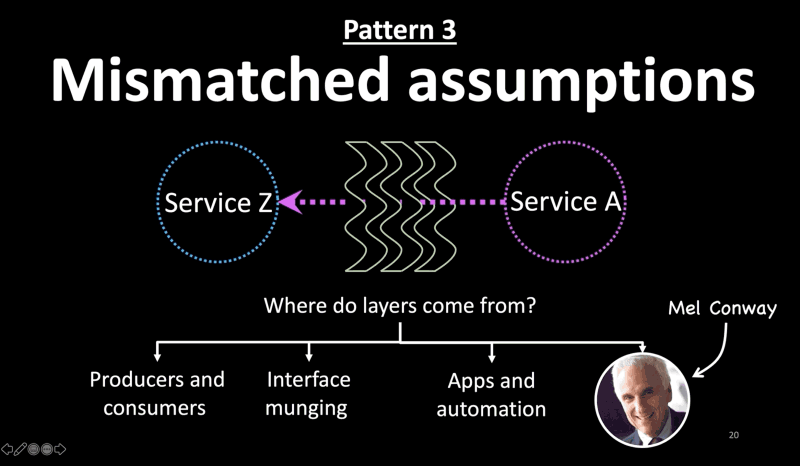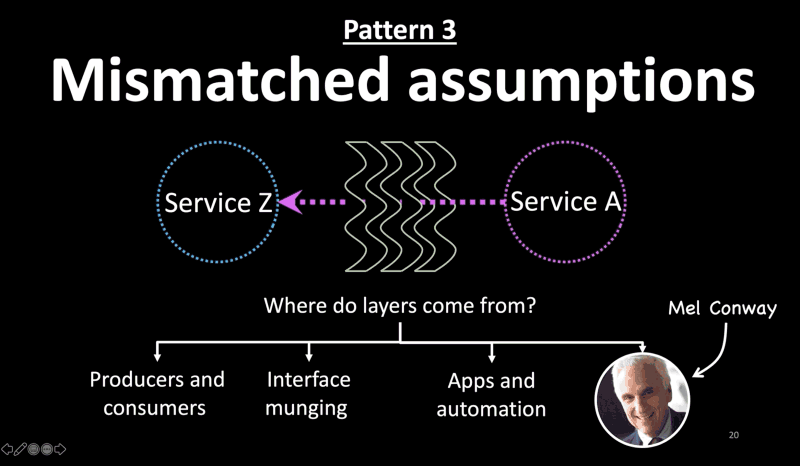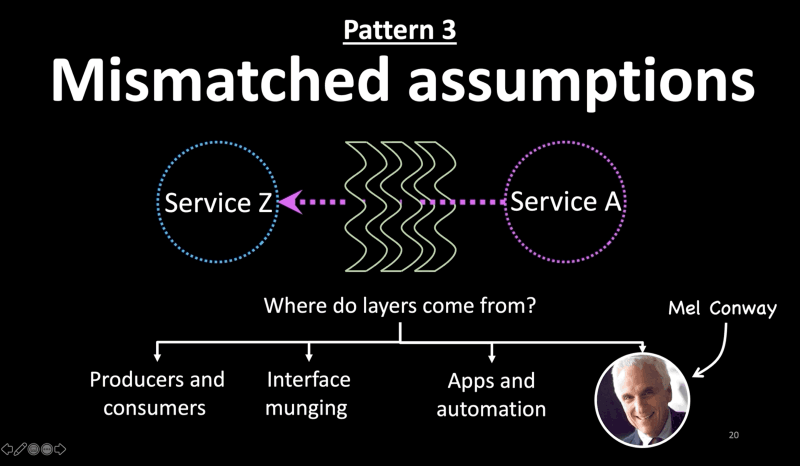
- The third pattern I noticed is mismatched assumptions between layers. Production environments are large distributed systems with several layers between most components.
- Each of those layers may make different assumptions about interfaces, behavior, scale, latency, availability, etc, and you may not know when you’re violating those assumptions.
- But where do layers come from?
- Layers between producers and consumers in a service-oriented architecture.
- Or, wrappers on wrappers to fix interfaces or data munging
- Or, between apps and automation platforms those rely on. For instance, a monitoring agent can make a node unavailable when it is just busy processing a request and waiting for a downstream system to respond.
- Sometimes, we create layers to work-around organizational issues, thanks to Mel Conway. Those layers make their own assumptions about their downstream services.
Pattern 4: Not the Network

- When I shared the outline of this talk with a colleague of mine, he remarked that “crap rolls downhill”, and the network gets blamed more often than it deserves.
- The network may be unreliable, but you can’t easily distinguish between a slow dependency or an impaired network. So, during incidents, teams start with the network only to realize factors like application slowness, bad timeouts, resource (CPU/mem) starvation, etc.
Pattern 5: Unknown

- Finally, a sufficiently large number of incidents have no clear reason for failure. They usually start with a key business metric going the wrong way. While you’re busy troubleshooting, the metric recovers on its own, and you don’t know why.
- Such incidents show that we don’t fully understand the dynamics of production systems.

- Let’s now look at some practices to improve. None of these are new techniques. Yet, I’m bringing these up to remind that improvements require systemic investments.
- The first practice I recommend is to progressively increase confidence in the delivery of production changes.
- I can not emphasize this practice enough. In order to go fast with continuous delivery, find ways to progressively increase confidence.
- Do whatever it takes to increase confidence in the change before (in test and pre-prod environments) making the change, and while making the change. Don’t consider passing tests in a pre-prod environment as a green signal to go full-steam with a change in prod.
- In this example here, the system is deployed in three independent fault domains. Choose independent data centers (like cloud regions) for those fault domains.
- Don’t make the same change, whether it is code or config, everywhere at the same time. Instead, introduce the change slowly.
- Progressive changes might feel like a slow approach. But only if you’re babysitting the rollout. Bake progressive delivery into your CI/CD instead.
Practice 2: Fail Partially
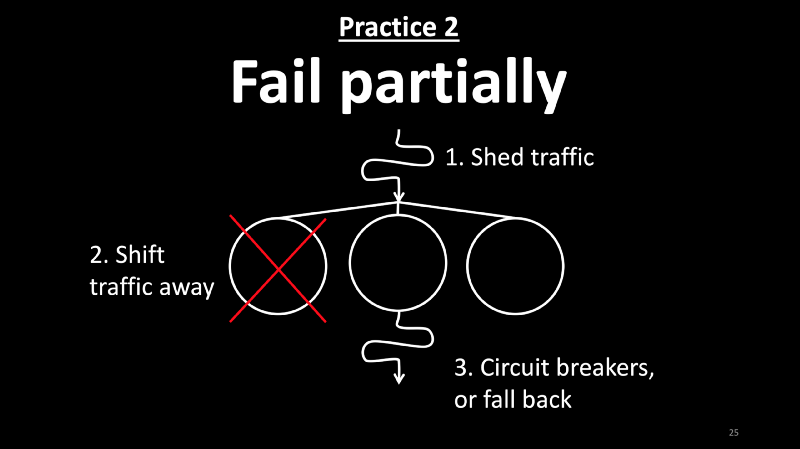
- When there is an incident, your first task should be to protect the customer and the business but not to debug to know what happened.
- You can afford to protect the customer and the business only when you invest in fail-safe mechanisms.
- In this slide, I’m illustrating three important mechanisms.
- First, the app is compartmentalized into three independent failure domains. When you spot an issue with one of these, you may be able to shift traffic away from it to healthy fault domains. You can also use the same pattern to scale out your service.
- Second, you may shed some part of the traffic to preserve the rest of the traffic. You may apply rate limits, drop connections, show shunt pages, and send 503s.
- Third, implement circuit breaks and falls backs for dependencies so you can limit cascading failures.
Practice 3: Vaccinate

- Another name for this is “chaos testing”. I prefer vaccination because it makes the point of introducing faults to build immunity.
- When planning your tests, incorporate tests to exercise fault domain boundaries, assumptions of scale and latency between layers, scale up and scale down conditions, as well as traffic shedding and traffic shifting.

- The fourth practice in my list is to not away from incidents after recovery. Learning from an incident starts after the incident.
- First, clean up after the incident. Leftovers usually contribute to config drift.
- Second, write post-mortems. In addition to looking for contributing factors, think of systemic improvements to make.
- Validate any fixes. Let those fixes form a new hypothesis for your chaos tests.
- Yes, these are time-consuming activities. Do spend the time to learn.

- Time and resources are always finite, while our backlogs are nearly infinite. Every team has enough work to do for years to come.
- Amidst all this work, how do you influence the prioritization of work to improve production stability? How do you convince your team, or your manager, or person in charge of making prioritization decisions to invest in resiliency related improvements?
- Examples: Architecting fault domains, investing in chaos testing, validating fixes after incidents, etc take time.
- Learn to attribute value to those types of work. Learn to measure the effects of incidents like lost revenue, customers, time, productivity, etc.
- If you’re not able to make such value-based arguments, you may remain frustrated.

- To summarize my talk, incidents provide an excellent way to learn about your architecture, people, processes, and culture.
- Study incidents. Form study groups to discover patterns from incidents. Patterns like the one we discussed here empower you to make value-based arguments to influence your teams.
- If you’ve time to do just one thing, invest in release safety.